Using Cache in Pipeline¶
In CI, pipelines are often used to perform tasks such as compiling and building. In modern languages, whether it's Java, NodeJS, Python, or Go, dependencies need to be downloaded to execute the build tasks. This process often consumes a large amount of network resources, slowing down the pipeline build speed and becoming a bottleneck in CI/CD, reducing our production efficiency.
Similarly, this includes cache files generated by syntax checks, cache files generated by Sonarqube scanning code. If we start running these processes from scratch every time, we will not be able to effectively utilize the cache mechanism of the tools themselves.
The application workspace itself provides a cache mechanism based on hostPathVolume in K8s, using the local path of the node to cache default paths such as /root/.m2, /home/jenkins/go/pkg, /root/.cache/pip.
However, in the multi-tenant scenario of DCE 5.0, more users want to maintain cache isolation to avoid intrusion and conflicts. Here, we introduce a cache mechanism based on the Jenkins plugin Job Cacher.
Through Job Cacher, we can use AWS S3 or S3-compatible storage systems (such as MinIO) to achieve pipeline-level cache isolation.
Preparation¶
-
Provide an S3 or S3-like storage backend, you can refer to Create MinIO Instance - DaoCloud Enterprise to create a MinIO on DCE 5.0, create a bucket, and prepare
access keyandsecret.
-
In Jenkins, go to Manage Jenkins -> Manage Plugins and install the job-cacher plugin:
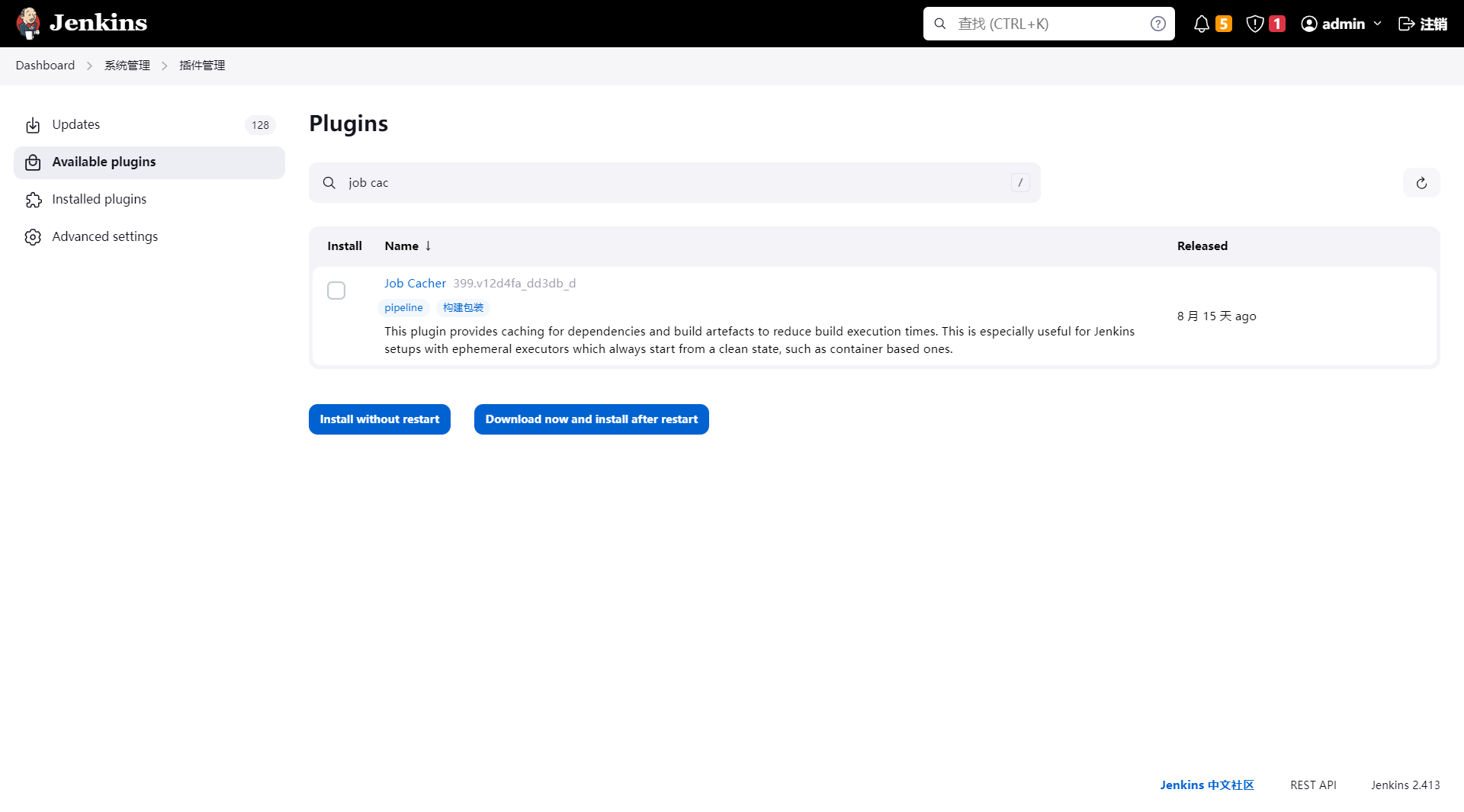
-
If you want to use S3 storage, you also need to install the following plugins:
- groupId: org.jenkins-ci.plugins artifactId: aws-credentials source: version: 218.v1b_e9466ec5da_ - groupId: org.jenkins-ci.plugins.aws-java-sdk artifactId: aws-java-sdk-minimal # (1)! source: version: 1.12.633-430.vf9a_e567a_244f - groupId: org.jenkins-ci.plugins artifactId: jackson2-api # (2)! source: version: 2.16.1-373.ve709c6871598- dependency for aws-credentials
- dependency for other plugins
Note
The Helm Chart provided by Amamba v0.3.2 and earlier corresponds to Jenkins v2.414. It has been tested that this version of Job Cacher 399.v12d4fa_dd3db_d cannot correctly recognize S3 configuration. Pay attention to using an upgraded version of Jenkins and Job Cacher.
Configuration¶
In the Manage Jenkins interface, configure the parameters for S3 as follows:
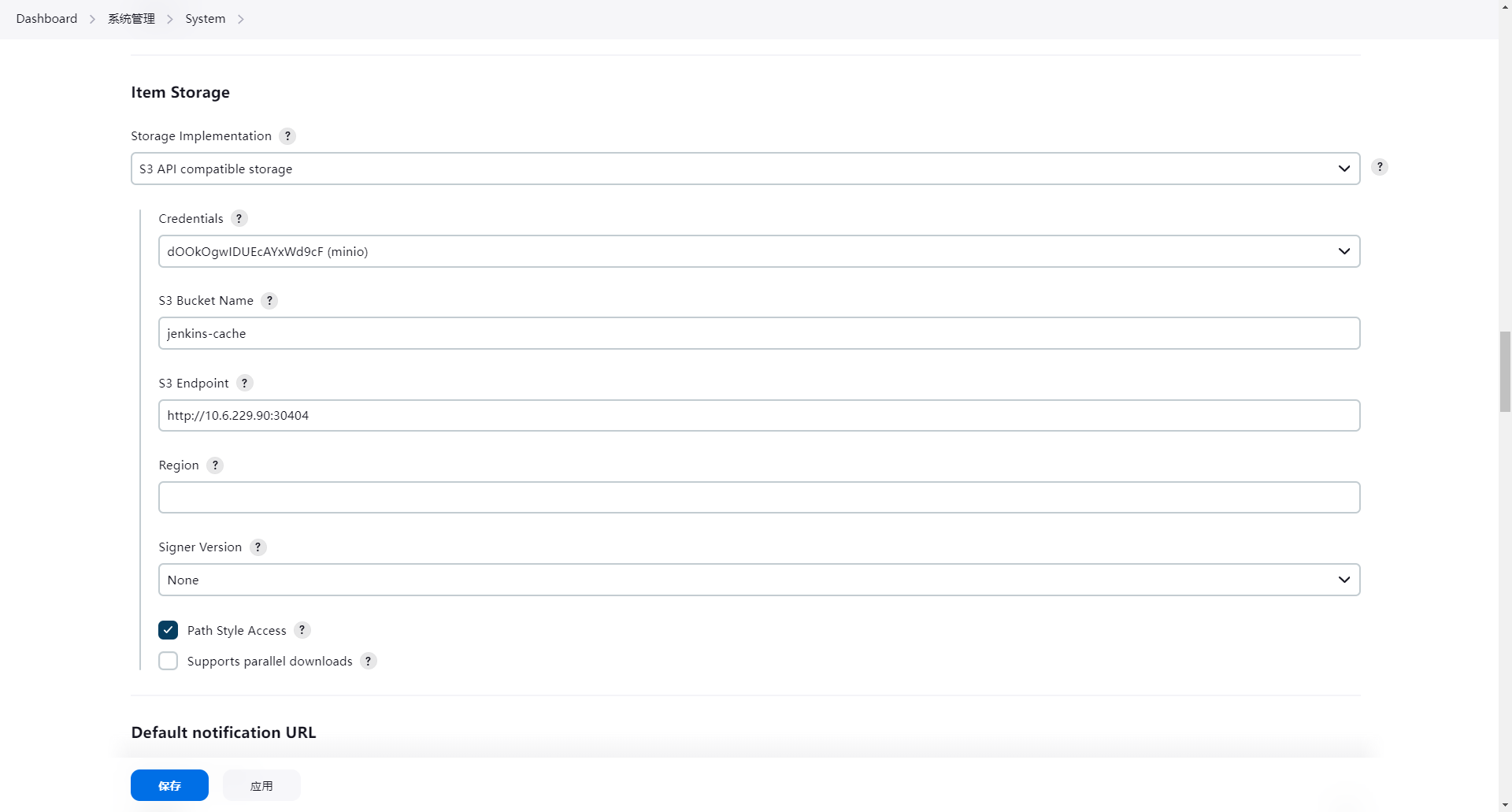
Alternatively, you can modify the ConfigMap via CasC to persist the configuration.
An example of the corrected YAML is as follows:
unclassified:
...
globalItemStorage:
storage:
nonAWSS3:
bucketName: jenkins-cache
credentialsId: dOOkOgwIDUEcAYxWd9cF
endpoint: http://10.6.229.90:30404
region: Auto
signerVersion:
parallelDownloads: true
pathStyleAccess: false
Usage¶
After completing the above configuration, we can use the cache function provided by Job Cacher in the Jenkinsfile. For example, in the following pipeline:
pipeline {
agent {
node {
label 'nodejs'
}
}
stages {
stage('clone') {
steps {
git(url: 'https://gitlab.daocloud.cn/ndx/engineering/application/amamba-test-resource.git', branch: 'main', credentialsId: 'git-amamba-test')
}
}
stage('test') {
steps {
sh 'git rev-parse HEAD > .cache'
cache(caches: [
arbitraryFileCache(
path: "pipeline-template/nodejs/node_modules",
includes: "**/*",
cacheValidityDecidingFile: ".cache",
)
]){
sh 'cd pipeline-template/nodejs/ && npm install && npm run build && npm install jest jest-junit && npx jest --reporters=default --reporters=jest-junit'
junit 'pipeline-template/nodejs/junit.xml'
}
}
}
}
}
This pipeline defines two stages, clone and test. In the test stage, we cache all files under node_modules to avoid fetching npm packages every time. We also define the .cache file as the unique identifier for the cache. This means that once there is any update in the current branch, the cache will become invalid and npm packages will be fetched again.
After completion, you can see that the second run of the pipeline significantly reduces the time:
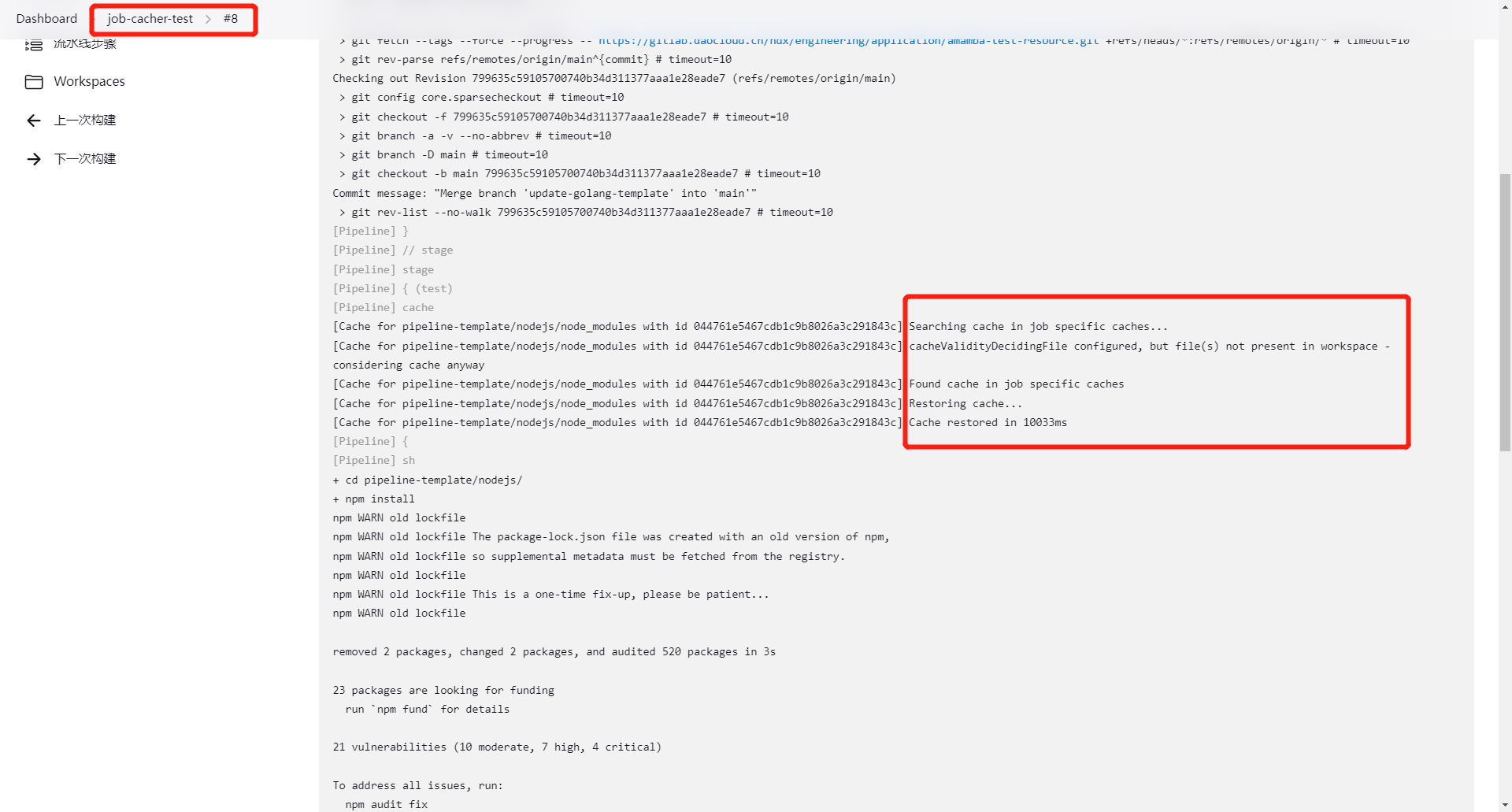
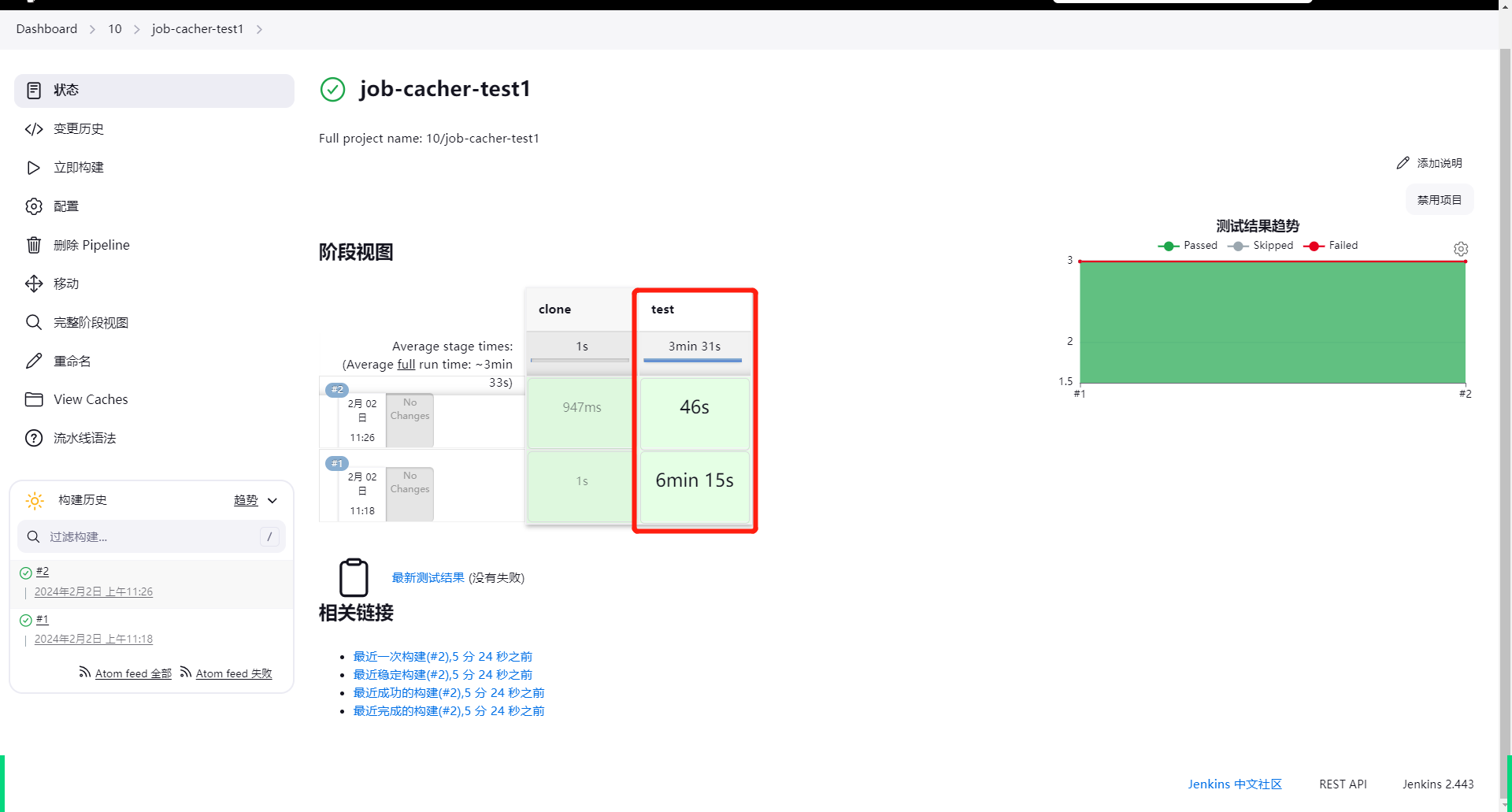
For more options, you can refer to the documentation: Job Cacher | Jenkins plugin
Other¶
- About Performance: job-cacher is also implemented based on
MasterToSlaveFileCallable, which is based on remote calls to directly upload and download in the agent, rather than the agent -> controller -> S3 way; - About Cache Size: job-cacher supports various compression algorithms, including
ZIP,TARGZ,TARGZ_BEST_SPEED,TAR_ZSTD,TAR, withTARGZas the default; - About Cache Cleanup: job-cacher supports setting
maxCacheSizeper pipeline.